NN의 꽃 RNN 이야기
Sequence data
우리가 사용하는 data는 sequence data가 많다. 음성인식이나 자연어 등등.
하나의 단어만 이해한다고해서 전체의 맥락을 이해하는 것이 아니라. 앞의 단어들을 모두 이해한 다음 맥락을 이해할 수 있다. 이것이 sequence data이다.

기존의 neural network나 convolution neural network의 경우 어떤 x라는 입력이 있으면 바로 출력으로 나타나는 간단한 형태였기 때문에 sequence data와 같은 형태의 data를 처리하기 힘들었다. 그래서 다음과 같은 형태의 네트워크를 만들었다.

sequence data를 생각했을 때, 한 데이터를 처리하고 다음 데이터를 처리할 때 이전의 연산의 결과가 다음 연산에 영향을 미쳐야 된다. 그렇기 때문에 위와 같은 형태의 네트워크가 만들어지게 되었다. 위의 구조는 실제 구현할 때 아래와 같은 형태를 띄게 된다.

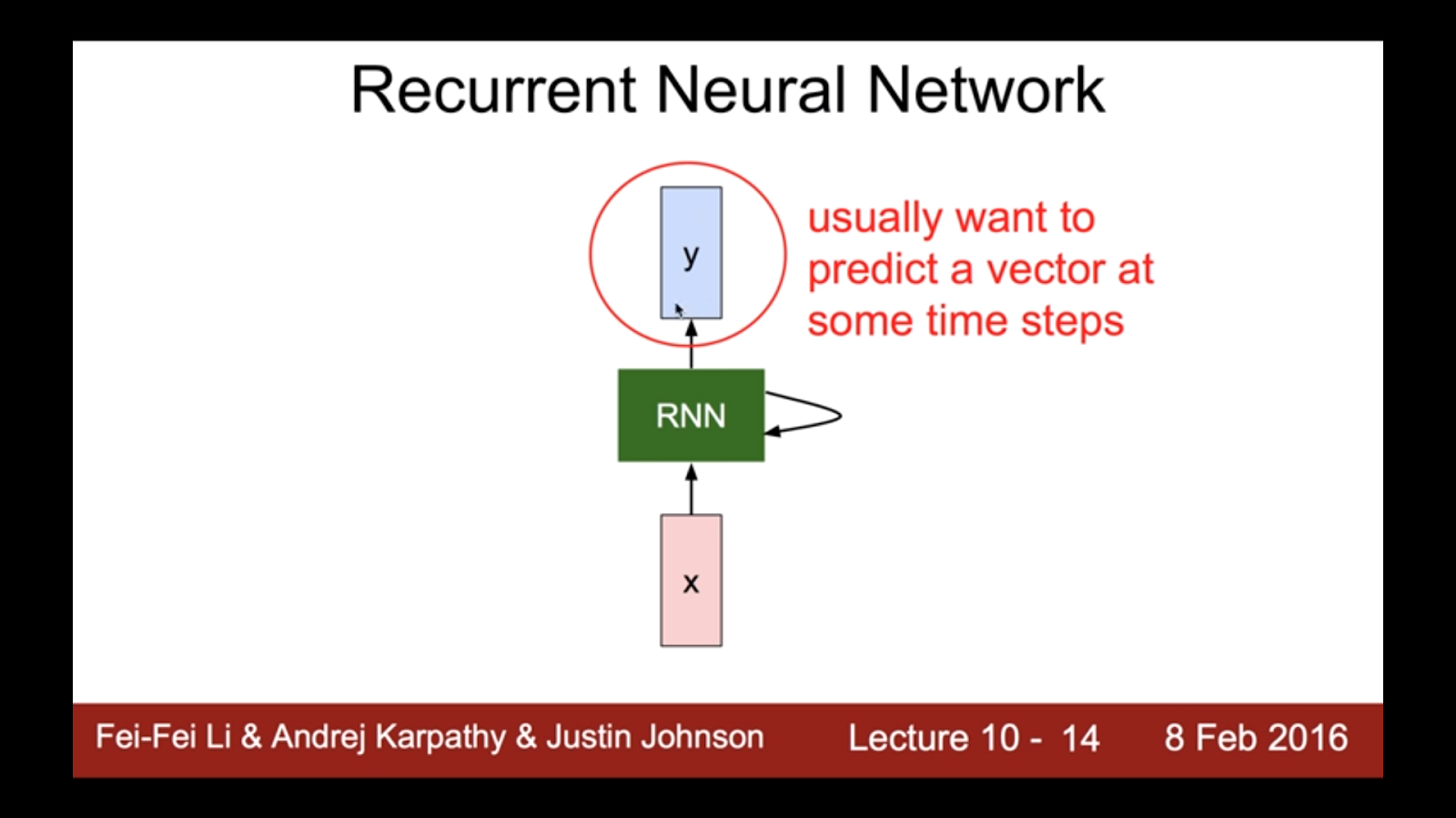
Recurrent Neural Network
x라는 입력이 있을 때, RNN이라는 연산을 통해 계산을 하고 계산한 결과가 다시 자기 입력이 되는 것을 말한다. 우리는 각 RNN 셀에서 연산의 결과로 y값을 뽑아낼 수 있다.
그렇다면 어떻게 계산할까? 기본적인 function은 WX이다.

계산할 때 주의할 것은 새로운 state를 계산할 때, 이전의 state를 사용하는 것과 어떤 state를 계산할 때도 같은 function을 사용한다는 것을 주의해야 한다.
우리가 사용하는 data는 sequence data가 많다. 음성인식이나 자연어 등등.
하나의 단어만 이해한다고해서 전체의 맥락을 이해하는 것이 아니라. 앞의 단어들을 모두 이해한 다음 맥락을 이해할 수 있다. 이것이 sequence data이다.

기존의 neural network나 convolution neural network의 경우 어떤 x라는 입력이 있으면 바로 출력으로 나타나는 간단한 형태였기 때문에 sequence data와 같은 형태의 data를 처리하기 힘들었다. 그래서 다음과 같은 형태의 네트워크를 만들었다.

sequence data를 생각했을 때, 한 데이터를 처리하고 다음 데이터를 처리할 때 이전의 연산의 결과가 다음 연산에 영향을 미쳐야 된다. 그렇기 때문에 위와 같은 형태의 네트워크가 만들어지게 되었다. 위의 구조는 실제 구현할 때 아래와 같은 형태를 띄게 된다.

Recurrent Neural Network
x라는 입력이 있을 때, RNN이라는 연산을 통해 계산을 하고 계산한 결과가 다시 자기 입력이 되는 것을 말한다. 우리는 각 RNN 셀에서 연산의 결과로 y값을 뽑아낼 수 있다.
그렇다면 어떻게 계산할까? 기본적인 function은 WX이다.

계산할 때 주의할 것은 새로운 state를 계산할 때, 이전의 state를 사용하는 것과 어떤 state를 계산할 때도 같은 function을 사용한다는 것을 주의해야 한다.
(Vanilla) Recurrent Neural Network
가장 기초가 되는 RNN 계산방법은 (Vanilla) Recurrent Neural Network 방법이다.

이 방법에서 사용되는 function도 딥러닝의 기본적인 함수인 WX이다. 이전 state와 새로운 state 각각에 W를 만들어준 후 tanh한다(사용되는 W는 새로운 state에 사용할 W1과 예전의 state에 사용할 W2, y값을 뽑아내기 위해 사용할 W3, 총 3개이다.).
그리고 y값을 뽑아낼때는 새로운 W를 곱해준 후 y 값을 추출할 수 있다. y가 몇개의 vector를 가질까는 W의 vector의 모양에 따라서 정해진다.


Character-level language model
RNN을 통해서 Character-level language model을 만들 수 있다. Character-level language model은 hello라는 입력 값을 주고 h 라는 입력이 들어왔을 때 출력으로 l을 출력할 수 있는 모델을 말한다.
4가지 종류의 글자가 있기 때문에 크기가 4인 벡터로 처리한다. multi-nomial classification에서 봤던 것처럼 4가지 중에서 하나를 선택하게 하려고 한다. 몇 번째 값이 켜졌느냐에 따라 순서대로 h, e, l, o가 된다.

공식에서 볼 수 있는 것처럼 h의 값과 x의 값을 W와 계산하여 더한 후 tanh 함수에 전달하면 hidden layer에서 볼 수 있는 값이 차례대로 만들어진다.

tanh 함수는 sigmoid 함수 중의 하나로 처음 나왔던 sigmoid를 개량한 버전이다. 기존의 sigmoid 함수가 0에서 1 사이의 값을 반환하는데, tanh 함수는 -1에서 1 사이의 값이 반환하도록 개량했다. 현재 상태를 가리키는 ht는 tanh 함수의 반환값이므로 -1과 1 사이의 값이 된다. 그래서 hidden layer에 있는 값들도 해당 범위에 존재하게 된다.
최종적으로는 모든 단계에서 값을 예측하고 실제 값과 맞는지 비교할 수 있다.

위의 자료에서 보면 e를 입력했을 때, l값이 나와야 하지만 o값(1.2로 값이 제일 크니까)이 나왔다. error가 생겼다고 할 수 있다.
이럴 경우 cost를 계산하여 error를 보완하고 학습할 수 있다. 여기서는 softmax에 해당되는 cost function을 사용하여 cost를 계산할 수 있다. 계산 값으로 나온 4개의 값을 모두 더한 후 cost를 평균내면 학습을 시킬 수 있다.
가장 기초가 되는 RNN 계산방법은 (Vanilla) Recurrent Neural Network 방법이다.

이 방법에서 사용되는 function도 딥러닝의 기본적인 함수인 WX이다. 이전 state와 새로운 state 각각에 W를 만들어준 후 tanh한다(사용되는 W는 새로운 state에 사용할 W1과 예전의 state에 사용할 W2, y값을 뽑아내기 위해 사용할 W3, 총 3개이다.).
그리고 y값을 뽑아낼때는 새로운 W를 곱해준 후 y 값을 추출할 수 있다. y가 몇개의 vector를 가질까는 W의 vector의 모양에 따라서 정해진다.

Character-level language model
RNN을 통해서 Character-level language model을 만들 수 있다. Character-level language model은 hello라는 입력 값을 주고 h 라는 입력이 들어왔을 때 출력으로 l을 출력할 수 있는 모델을 말한다.
4가지 종류의 글자가 있기 때문에 크기가 4인 벡터로 처리한다. multi-nomial classification에서 봤던 것처럼 4가지 중에서 하나를 선택하게 하려고 한다. 몇 번째 값이 켜졌느냐에 따라 순서대로 h, e, l, o가 된다.

공식에서 볼 수 있는 것처럼 h의 값과 x의 값을 W와 계산하여 더한 후 tanh 함수에 전달하면 hidden layer에서 볼 수 있는 값이 차례대로 만들어진다.

tanh 함수는 sigmoid 함수 중의 하나로 처음 나왔던 sigmoid를 개량한 버전이다. 기존의 sigmoid 함수가 0에서 1 사이의 값을 반환하는데, tanh 함수는 -1에서 1 사이의 값이 반환하도록 개량했다. 현재 상태를 가리키는 ht는 tanh 함수의 반환값이므로 -1과 1 사이의 값이 된다. 그래서 hidden layer에 있는 값들도 해당 범위에 존재하게 된다.
최종적으로는 모든 단계에서 값을 예측하고 실제 값과 맞는지 비교할 수 있다.

위의 자료에서 보면 e를 입력했을 때, l값이 나와야 하지만 o값(1.2로 값이 제일 크니까)이 나왔다. error가 생겼다고 할 수 있다.
이럴 경우 cost를 계산하여 error를 보완하고 학습할 수 있다. 여기서는 softmax에 해당되는 cost function을 사용하여 cost를 계산할 수 있다. 계산 값으로 나온 4개의 값을 모두 더한 후 cost를 평균내면 학습을 시킬 수 있다.
RNN applications
RNN을 통해 할 수 있는 것들은 다음과 같다.

아래의 그림은 바닐라 RNN이다. 가장 단순한 형태로 1대1(one-to-one) 기반의 모델이다.

1대다(one-to-many) 기반의 모델로 이미지에 대해 설명을 붙일 때 사용한다. 한 장의 그림에 대해 "소년이 사과를 고르고 있다"처럼 여러 개의 단어 형태로 표현될 수 있다.

다대1(many-to-one) 형태의 모델로 여러 개의 입력에 대해 하나의 결과를 만들어 준다. 우리가 하는 말을 통해 우리의 심리 상태를 "안정", "불안", "공포" 등의 한 단어로 결과를 예측할 때 사용된다. sentiment는 감정을 의미한다.

다대다(many-to-many] 형태의 모델로 기계 번역에서 사용된다. 여러 개의 단어로 구성된 문장을 입력으로 받아서 여러 개의 단어로 구성된 문장을 반환한다. 구글 번역기 등이 이에 해당한다.

다대다(many-to-many) 모델의 또 다른 형태다. 동영상같은 경우는 여러 개의 이미지 프레임에 대해 여러 개의 설명이나 번역 형태로 결과를 반환한다.

RNN도 여러 개의 layer를 두고 복잡한 형태로 구성할 수 있다. 아래는 위의 그림들을 다단계로 배치한 형태라고 보면 된다.

RNN 또한 layer가 많아지면서 복잡해지기 때문에 이를 극복할 수 있는 다양한 방법들이 소개되고 있다. 현재는 RNN이라고 하면 많은 경우 LSTM을 의미한다. 그리고 LSTM처럼 많이 사용되는 방법으로 한국의 조교수님께서 만든 GRU도 있다.

RNN을 통해 할 수 있는 것들은 다음과 같다.

아래의 그림은 바닐라 RNN이다. 가장 단순한 형태로 1대1(one-to-one) 기반의 모델이다.

1대다(one-to-many) 기반의 모델로 이미지에 대해 설명을 붙일 때 사용한다. 한 장의 그림에 대해 "소년이 사과를 고르고 있다"처럼 여러 개의 단어 형태로 표현될 수 있다.

다대1(many-to-one) 형태의 모델로 여러 개의 입력에 대해 하나의 결과를 만들어 준다. 우리가 하는 말을 통해 우리의 심리 상태를 "안정", "불안", "공포" 등의 한 단어로 결과를 예측할 때 사용된다. sentiment는 감정을 의미한다.

다대다(many-to-many] 형태의 모델로 기계 번역에서 사용된다. 여러 개의 단어로 구성된 문장을 입력으로 받아서 여러 개의 단어로 구성된 문장을 반환한다. 구글 번역기 등이 이에 해당한다.

다대다(many-to-many) 모델의 또 다른 형태다. 동영상같은 경우는 여러 개의 이미지 프레임에 대해 여러 개의 설명이나 번역 형태로 결과를 반환한다.

RNN도 여러 개의 layer를 두고 복잡한 형태로 구성할 수 있다. 아래는 위의 그림들을 다단계로 배치한 형태라고 보면 된다.

RNN 또한 layer가 많아지면서 복잡해지기 때문에 이를 극복할 수 있는 다양한 방법들이 소개되고 있다. 현재는 RNN이라고 하면 많은 경우 LSTM을 의미한다. 그리고 LSTM처럼 많이 사용되는 방법으로 한국의 조교수님께서 만든 GRU도 있다.

댓글 없음:
댓글 쓰기