개요
ConvNet의 Conv 레이어 만들기
Convolutional Neural Networks
입력을 나누어받는 고양이의 뉴런에서 착안하여 입력을 나눠 받아보자고 시작한 것이 Convolutional Neural Networks이다.
이미지를 나누어서 입력을 받는다고 하였을 때 아래와 같이 볼 수 있다.

입력을 자른 후 각각의 입력으로 넘기게 되는데 이 층을 Convolutional Layer라고 부른다. 그래서 전체의 이름이 Convolutional Networks라고 부른다.
만들어진 Convolutional Layer 사이에 RELU나 POOL을 넣어 계산한다. 이와 같이 CONV 레이어와 RELU, POOL을 반복하고 마지막에 FC을 구성하여 최종적인 Labeling을 할 수 있다.

**POOL과 RELU는 어떤 층이었지? 이 층이 레이어 사이에 넣어질 때 규칙이 있는 건가? POOL의 개수가 적어보이는데 어떤 이유가 있는거지?
레이어별로 어떻게 진행되는지 알아보자.
입력을 이미지로 받는다고 했을 때, 이미지는 다음과 같이 나타낼 수 있다. width * height * depth는 이미지를 vector의 형태로 나타낸 것인데, depth는 color 값을 나타낸다.
Conv에서는 이미지를 하나의 입력으로 받지 않고 이미지를 작게 나눠서 단위별로 처리한다. 이때 지정된 단위별로 처리하는 것을 filter라고 한다(filter 크기를 지정할 때, width와 height의 값은 사용자의 설정에 따라 달라질 수 있으나 depth는 색의 값이므로 변하지 않는다.).

여기서는 5 * 5로 값을 지정하고 5 * 5로 이미지를 읽어낸다. filter는 아래의 그림과 같이 5 * 5로 지정된 단위만큼을 읽어온 후, 수학적 처리에 의해 한 점만 뽑아낸다.

어떻게 한 점으로 만들 수 있을까?
그동안 배웠던 Wx + b를 통해서 만들 수 있다. 읽어온 값(5 * 5 * 3)을 x라 하고 Wx + b의 식에 대입하여 값을 만들 수 있다(Wx + b는 x가 1개일 경우나 여러 개(feature의 개수)일 경우에 대해서도 계산할 수 있기 때문에 유용하게 사용할 수 있다.).
여기서 W이 한 점으로 처리하는데 큰 영향을 미치기 때문에 W를 filter의 값이라고 생각하면 된다. 여기서 ReLU의 값을 넣어주고 싶으면 ReLU(Wx + b)와 같이 기본 식에 ReLU를 포함하면 된다.
** ReLU가 뭐였더라.. 그냥 식인가 그래프인가. 알고리즘인가..

같은 filter(W)를 가지고 이미지를 계산해보자.

이런 과정을 거치게 되면 우리는 몇개의 값을 모을 수 있을까? 이 부분이 중요한 이유는 네트워크를 구성할 때 이 값을 알아야 W의 개수도 정하고 어떻게 넘길 것인가도 설계할 수 있다.
다음 예제를 통해 알아보자.
7 * 7 input을 3 * 3 filter를 가지고 움직이면 몇 개의 점이 나올까?


** 왜 한칸씩 움직이지?
filter를 한 칸씩 움직이는 것을 Stride 1이라고 한다. 그러므로 위와 같이 움직이는 것을 Stride 1일 때, 총 5 * 5의 점을 뽑아낼 수 있다고 하면 된다.
Stride를 2라고 잡으면 아래와 같다.



Stride 2일 때, 3 * 3 output을 낸다.
이것을 일반화해보면 Stride 와 이미지의 크기를 통해 output의 값을 알아낼 수 있다(output을 알아내면 W의 개수도 정하고 어떻게 넘기는지 설계할 수 있다.).

위의 설명한 것과 같이 이미지를 축소시키면 입력값을 나눠서 받게 되고 **계산하기 좋은 값이 된다. 하지만 이미지를 축소하게 되면 정보를 잃어버리게 된다는 단점이 있다.
그래서 보통 Conv을 이용할 때는 padding이라는 개념을 사용한다. idea는 이미지의 테두리에 0의 값을 가지는 픽셀 테두리를 만들어주는 것이다.

이 idea의 장점은

입력을 나누어받는 고양이의 뉴런에서 착안하여 입력을 나눠 받아보자고 시작한 것이 Convolutional Neural Networks이다.
이미지를 나누어서 입력을 받는다고 하였을 때 아래와 같이 볼 수 있다.

입력을 자른 후 각각의 입력으로 넘기게 되는데 이 층을 Convolutional Layer라고 부른다. 그래서 전체의 이름이 Convolutional Networks라고 부른다.
만들어진 Convolutional Layer 사이에 RELU나 POOL을 넣어 계산한다. 이와 같이 CONV 레이어와 RELU, POOL을 반복하고 마지막에 FC을 구성하여 최종적인 Labeling을 할 수 있다.

**POOL과 RELU는 어떤 층이었지? 이 층이 레이어 사이에 넣어질 때 규칙이 있는 건가? POOL의 개수가 적어보이는데 어떤 이유가 있는거지?
레이어별로 어떻게 진행되는지 알아보자.
입력을 이미지로 받는다고 했을 때, 이미지는 다음과 같이 나타낼 수 있다. width * height * depth는 이미지를 vector의 형태로 나타낸 것인데, depth는 color 값을 나타낸다.
Conv에서는 이미지를 하나의 입력으로 받지 않고 이미지를 작게 나눠서 단위별로 처리한다. 이때 지정된 단위별로 처리하는 것을 filter라고 한다(filter 크기를 지정할 때, width와 height의 값은 사용자의 설정에 따라 달라질 수 있으나 depth는 색의 값이므로 변하지 않는다.).

여기서는 5 * 5로 값을 지정하고 5 * 5로 이미지를 읽어낸다. filter는 아래의 그림과 같이 5 * 5로 지정된 단위만큼을 읽어온 후, 수학적 처리에 의해 한 점만 뽑아낸다.

어떻게 한 점으로 만들 수 있을까?
그동안 배웠던 Wx + b를 통해서 만들 수 있다. 읽어온 값(5 * 5 * 3)을 x라 하고 Wx + b의 식에 대입하여 값을 만들 수 있다(Wx + b는 x가 1개일 경우나 여러 개(feature의 개수)일 경우에 대해서도 계산할 수 있기 때문에 유용하게 사용할 수 있다.).
여기서 W이 한 점으로 처리하는데 큰 영향을 미치기 때문에 W를 filter의 값이라고 생각하면 된다. 여기서 ReLU의 값을 넣어주고 싶으면 ReLU(Wx + b)와 같이 기본 식에 ReLU를 포함하면 된다.
** ReLU가 뭐였더라.. 그냥 식인가 그래프인가. 알고리즘인가..

같은 filter(W)를 가지고 이미지를 계산해보자.

이런 과정을 거치게 되면 우리는 몇개의 값을 모을 수 있을까? 이 부분이 중요한 이유는 네트워크를 구성할 때 이 값을 알아야 W의 개수도 정하고 어떻게 넘길 것인가도 설계할 수 있다.
다음 예제를 통해 알아보자.
7 * 7 input을 3 * 3 filter를 가지고 움직이면 몇 개의 점이 나올까?


** 왜 한칸씩 움직이지?
filter를 한 칸씩 움직이는 것을 Stride 1이라고 한다. 그러므로 위와 같이 움직이는 것을 Stride 1일 때, 총 5 * 5의 점을 뽑아낼 수 있다고 하면 된다.
Stride를 2라고 잡으면 아래와 같다.



Stride 2일 때, 3 * 3 output을 낸다.
이것을 일반화해보면 Stride 와 이미지의 크기를 통해 output의 값을 알아낼 수 있다(output을 알아내면 W의 개수도 정하고 어떻게 넘기는지 설계할 수 있다.).

위의 설명한 것과 같이 이미지를 축소시키면 입력값을 나눠서 받게 되고 **계산하기 좋은 값이 된다. 하지만 이미지를 축소하게 되면 정보를 잃어버리게 된다는 단점이 있다.
그래서 보통 Conv을 이용할 때는 padding이라는 개념을 사용한다. idea는 이미지의 테두리에 0의 값을 가지는 픽셀 테두리를 만들어주는 것이다.

이 idea의 장점은
- 그림이 급격하게 작아지는 것을 방지할 수 있다.
- 이미지의 모서리를 Network에 알려줄 수 있다.
는 점이다.
pad를 넣을 경우 output의 값은 어떻게 나올까? pad를 하게 되므로 input 값은 7 * 7에서 9 * 9로 바뀌게 된다. 그 후 같은 공식으로 계산해주면

7 * 7로 나오게 된다. 이 얘기는 7 * 7의 값을 넣었을 때, 같은 사이즈로 값이 나오게 되는 것을 의미한다.
한 Conv는 위와 같이 Layer를 만드는 과정을 반복하는데, 주의할 점은 Layer 별로 새로운 filter를 사용한다는 것이다(깊이 값 = layer의 개수 = 필터의 개수).


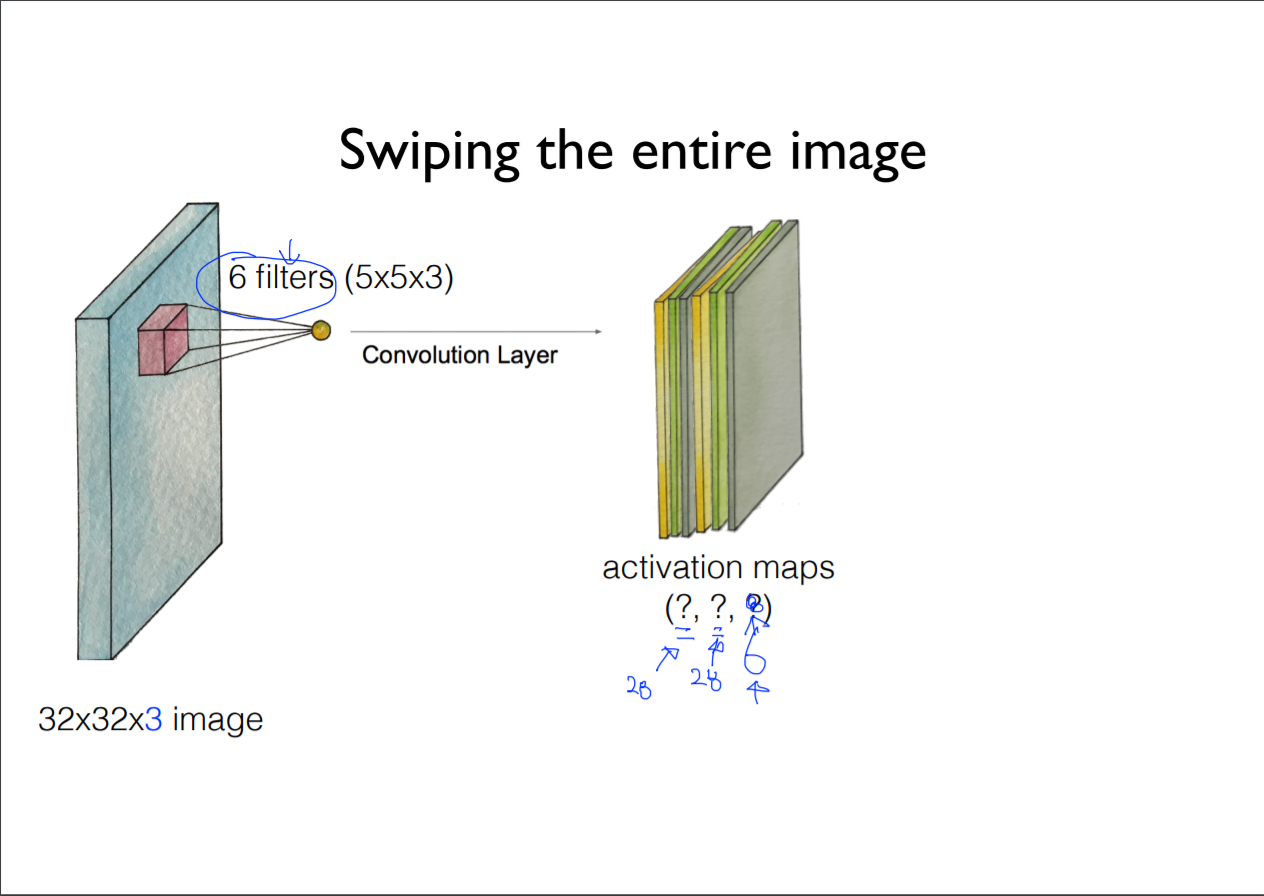
** 28 * 28?이 어떻게 나온거지
이런 성질을 이용하여 출력의 width, height, depth 값을 모두 알 수 있다.
이런 Conv과정을 거쳐 나온 것을 Activation Map이라고 하는데, Activation Map은 다시 Conv과정을 반복할 수 있다. 여러번 이 과정을 반복하면 이런식으로 Convolution Layer가 되는 것이다.

여기서 생각해볼 수 있는 것이 얼마나 많은 weight의 variables의 개수가 얼마나 될까?

weight의 개수는 5 * 5 * 3을 6개를 사용하였으므로, 5 * 5 * 3 * 6으로 값을 구할 수 있다.
어떻게 그 값들이 정해질까?
처음에는 값을 random하게 초기화하고 가진 데이터로 학습을 하게 된다.
ConvNet Max pooling과 Full Network
Pooling layer
Pooling layer는 간단하게 sampling이라고 보면 된다. 깊이는 몇개의 filter를 사용하는가에 따라 달라지는데, 여기서 1개의 Conv 안의 1개의 layer(1개의 filter로 뽑아낸 layer 값)을 뽑아낸다.

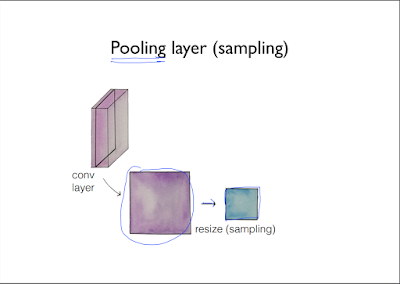
위와 같은 layer가 나오게 된다. 이 layer의 사이즈를 조정하는 것을 resize라고 한다.
이 값을 다시 쌓는다.

그리고 이렇게 쌓은 값을 다음 단계로 넘기는 것을 pooling이라 한다.
어떻게 pooling하는가? 다음과 같이 4 * 4 이미지가 있다고 생각하고, 2 * 2 filter를 stride 2로 사용해보자.

그럼 2 * 2 output 값이 나올텐데 그럼 필터의 어떤 값을 output으로 옮길 것인가? 가장 많이 사용되는 방법은 MAX POOLING 가장 큰 값을 옮기는 것이다(이 방법 때문에 sampling이라고도 부르는 것이다.).)

CONV와 RELU, POOL과 같은 과정을 어떻게 쌓을 것인가는 사용자의 선택사항이다. CONV 후 POOL을 해도 된다. 그런 다음 보통 마지막에 POOL을 하면 된다.
** 마지막에는 꼭 POOL을 해야하는 건가 통상적으로 한다는건가?

Pooling layer는 간단하게 sampling이라고 보면 된다. 깊이는 몇개의 filter를 사용하는가에 따라 달라지는데, 여기서 1개의 Conv 안의 1개의 layer(1개의 filter로 뽑아낸 layer 값)을 뽑아낸다.


위와 같은 layer가 나오게 된다. 이 layer의 사이즈를 조정하는 것을 resize라고 한다.
이 값을 다시 쌓는다.

그리고 이렇게 쌓은 값을 다음 단계로 넘기는 것을 pooling이라 한다.
어떻게 pooling하는가? 다음과 같이 4 * 4 이미지가 있다고 생각하고, 2 * 2 filter를 stride 2로 사용해보자.

그럼 2 * 2 output 값이 나올텐데 그럼 필터의 어떤 값을 output으로 옮길 것인가? 가장 많이 사용되는 방법은 MAX POOLING 가장 큰 값을 옮기는 것이다(이 방법 때문에 sampling이라고도 부르는 것이다.).)

CONV와 RELU, POOL과 같은 과정을 어떻게 쌓을 것인가는 사용자의 선택사항이다. CONV 후 POOL을 해도 된다. 그런 다음 보통 마지막에 POOL을 하면 된다.
** 마지막에는 꼭 POOL을 해야하는 건가 통상적으로 한다는건가?
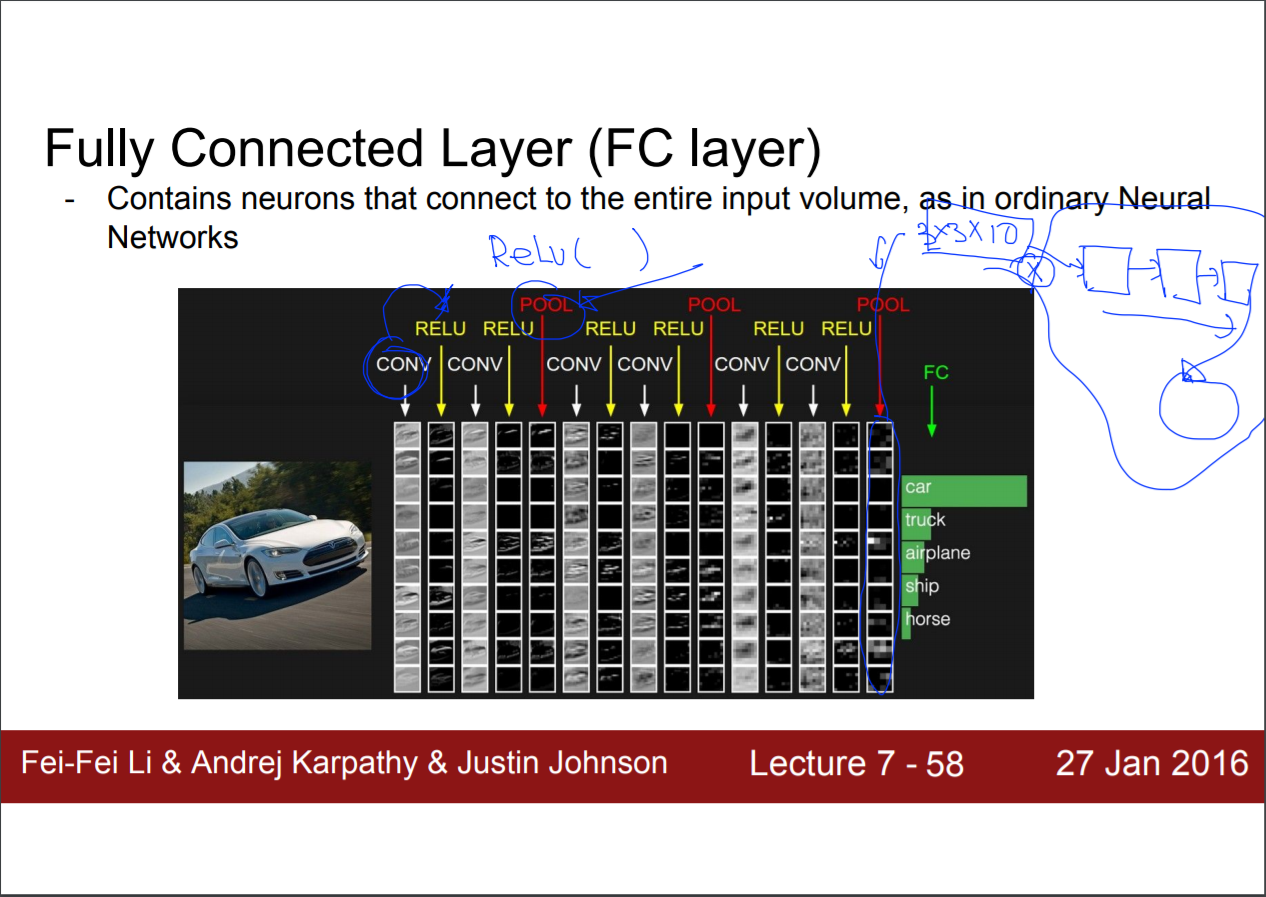
ConvNet의 활용 예
위과 같은 CNN의 기본적인 구조에 대해 어떤 식으로 응용이 가능한지, 사람들이 어떻게 응용했는지 알아보도록 하자.

NROM는 요즘은 보통 사용하지 않는다. 하지 않아도 상관없기 때문이다.




깊이가 굉장히 깊은데, 깊이가 깊어지면 학습이 어렵지 않을까? 라는 생각이 들 것이다. ResNet에서는 다음과 같은 방법을 사용하였다.

중간의 값을 뛰어서 앞으로 추월을 시킨다. 이게 왜 학습이 잘 되는지 설명하기는 어렵다.

값이 하나로 합쳐진다고 볼 수 있으므로, 학습시킬 때 layer가 깊지 않은 것으로 받아들 일 수 있다. 사실 학습이 잘되는 원인이 밝혀지지는 않았다(2015 당시).


이미지만 처리하는 것이 아니라 다양하게 사용할 수 있다. text에도 가능하다.

마지막으로 AlphaGo.


논문의 일부에서 볼 수 있다.
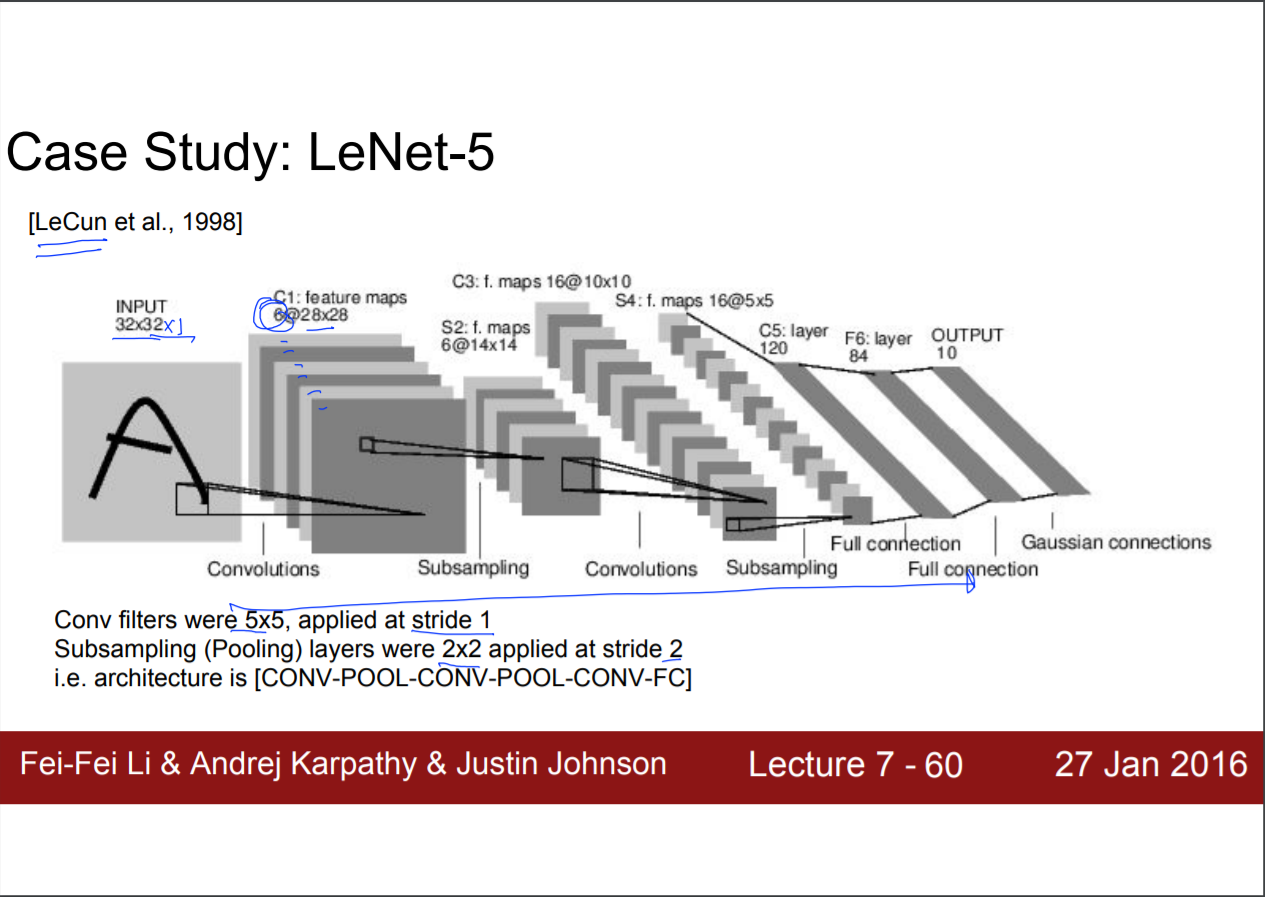
NROM는 요즘은 보통 사용하지 않는다. 하지 않아도 상관없기 때문이다.




깊이가 굉장히 깊은데, 깊이가 깊어지면 학습이 어렵지 않을까? 라는 생각이 들 것이다. ResNet에서는 다음과 같은 방법을 사용하였다.

중간의 값을 뛰어서 앞으로 추월을 시킨다. 이게 왜 학습이 잘 되는지 설명하기는 어렵다.

값이 하나로 합쳐진다고 볼 수 있으므로, 학습시킬 때 layer가 깊지 않은 것으로 받아들 일 수 있다. 사실 학습이 잘되는 원인이 밝혀지지는 않았다(2015 당시).


이미지만 처리하는 것이 아니라 다양하게 사용할 수 있다. text에도 가능하다.

마지막으로 AlphaGo.


논문의 일부에서 볼 수 있다.
댓글 없음:
댓글 쓰기