요약
k-최근접 이웃 알고리즘
장점: 높은 정확도, 오류 데이터(outlier)에 둔감, 데이터에 대한 가정이 없음
단점: 계산 비용이 높음, 많은 메모리 요구
적용: 수치형 값, 명목형 값
장점: 높은 정확도, 오류 데이터(outlier)에 둔감, 데이터에 대한 가정이 없음
단점: 계산 비용이 높음, 많은 메모리 요구
적용: 수치형 값, 명목형 값
k-최근접 이웃 알고리즘(k-NN, k-Nearest Neighbor)이란?
k-NN은 머신러닝의 지도학습 중 분류 문제를 해결하기 위한 알고리즘이다. 분류 문제는 새로운 데이터가 들어왔을 때, 기존의 데이터 그룹 중에서 어떤 그룹에 속하는지를 분류하는 문제를 말한다.
k-NN은 새로운 데이터에서 몇 번째(k번째)로 가까운 데이터까지의 그룹을 살펴보고, 새로운 데이터를 분류하는 알고리즘이다.
알고리즘의 분류 방법은 아래와 같이 정리할 수 있다.
k-NN은 새로운 데이터에서 몇 번째(k번째)로 가까운 데이터까지의 그룹을 살펴보고, 새로운 데이터를 분류하는 알고리즘이다.
알고리즘의 분류 방법은 아래와 같이 정리할 수 있다.
- 분류 항목(labels)이 표시된 데이터를 준비한다.
- 분류 항목이 표시된 데이터를 훈련 데이터로 입력한다.
- 새로운 데이터가 주어지면, 훈련 데이터들과 비교한다.
- 가장 유사한 데이터(훈련 데이터)의 분류 항목을 살펴본다.
- (이때, 가장 유사한 데이터 상위 k개의 분류 항목을 살펴본다.)
- k개의 유사 데이터의 분류 항목 중 가장 많은 분류 항목을 새로운 데이터의 분류 항목으로 결정한다.
kNN 원리
구체적인 예를 통해 알고리즘을 이해해보자.
로맨스 영화와 액션 영화를 분류하는 간단한 예제를 살펴보자. 로맨스 영화와 액션 영화를 나누기 위해 '키스를 하는 장면'과 '발차기를 하는 장면'을 기준으로 한다고 하자.
'키스 장면'과 '발차기 장면'을 기준으로 영화를 나누면 아래와 같이 영화를 분류할 수 있다.


이 때, 새로운 데이터 '?'를 분류하려면, '?' 데이터와 분류된 영화들과의 거리를 모두 구한다.

위의 표는 '?'와의 거리를 구하여 내림차순으로 정렬한 것이다. 이제 이 영화들 중 거리가 가까운 k개의 영화를 찾아야 한다. k=3이라고 하자. 그러면 가장 가까운 영화는 'California Man', 'He's Not Really into Dudes', 'Beautiful Woman'이 된다.
kNN 알고리즘은 '?'의 영화 분류 항목을 정하기 위해 'California Man', 'He's Not Really into Dudes', 'Beautiful Woman' 들의 분류 항목 중에서 가장 많이 뽑힌 것을 선정한다. 즉, 세 영화는 모두 로맨스이기 때문에 '?'의 분류 항목은 로맨스 영화로 예측된다.
로맨스 영화와 액션 영화를 분류하는 간단한 예제를 살펴보자. 로맨스 영화와 액션 영화를 나누기 위해 '키스를 하는 장면'과 '발차기를 하는 장면'을 기준으로 한다고 하자.
'키스 장면'과 '발차기 장면'을 기준으로 영화를 나누면 아래와 같이 영화를 분류할 수 있다.


이 때, 새로운 데이터 '?'를 분류하려면, '?' 데이터와 분류된 영화들과의 거리를 모두 구한다.

위의 표는 '?'와의 거리를 구하여 내림차순으로 정렬한 것이다. 이제 이 영화들 중 거리가 가까운 k개의 영화를 찾아야 한다. k=3이라고 하자. 그러면 가장 가까운 영화는 'California Man', 'He's Not Really into Dudes', 'Beautiful Woman'이 된다.
kNN 알고리즘은 '?'의 영화 분류 항목을 정하기 위해 'California Man', 'He's Not Really into Dudes', 'Beautiful Woman' 들의 분류 항목 중에서 가장 많이 뽑힌 것을 선정한다. 즉, 세 영화는 모두 로맨스이기 때문에 '?'의 분류 항목은 로맨스 영화로 예측된다.
거리척도의 단위 문제 - 표준화(유클리드 거리)
kNN에서 데이터 간의 거리를 측정하는 데는 유클리드(Euclidian) 거리를 사용하여 계산된다. 두 벡터 간의 거리는 다음과 같이 구한다.
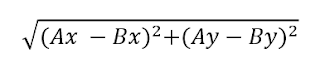
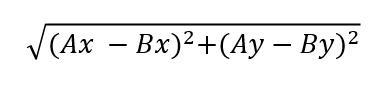
kNN 구현하기
새로운 데이터 즉, 분류할 데이터를 inX라고 하고 이 데이터를 kNN을 사용하여 분류하는 코드를 작성해보자.
kNN은 새로운 데이터와 이미 labels가 붙여진 데이터의 거리를 구하여 사용하는 것이므로 다음과 같이 의사코드를 작성할 수 있다.
위의 의사코드를 따라 구체적으로 코드를 구현해보자.
kNN은 새로운 데이터와 이미 labels가 붙여진 데이터의 거리를 구하여 사용하는 것이므로 다음과 같이 의사코드를 작성할 수 있다.
//데이터 집합(분류된 데이터 집합)들의 모든 측정값과 반복 //inX와 현재 측정값(분류된 데이터) 사이의 거리 계산 //오름차순으로 계산한 거리를 정렬 //inX와 거리가 가장 짧은 k개의 아이템 추출 //k개의 아이템에서 가장 많은 분류 항목 찾기 //inX의 분류 항목을 예측하기 위해 가장 많은 분류 항목을 반환
위의 의사코드를 따라 구체적으로 코드를 구현해보자.
//데이터 집합(분류된 데이터 집합)들의 모든 측정값과 반복 //inX와 현재 측정값(분류된 데이터) 사이의 거리 계산
difMat = tile(inX, (dataSetSize, 1)) - dataSet sqDiffMat = diffMat ** 2 sqDistances = sqDiffMat.sum(axis = 1) //오름차순으로 계산한 거리를 정렬 sortedDistIndicies = distances.argsort() ... //inX와 거리가 가장 짧은 k개의 아이템 추출 for i in range(k): //k개의 아이템에서 가장 많은 분류 항목 찾기 voteIlabel = labels[sortedDistIndicies[i]] classCount[voteIlabel] = classCount.get(voteIlabel, 0) + 1 //inX의 분류 항목을 예측하기 위해 가장 많은 분류 항목을 반환 sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True) return sortedClassCount[0][0]
""" inX: 분류할 입력 데이터 dataSet: 훈련 데이터 행렬 labels: 분류 항목 벡터 k: 투표에서 사용할 최근접 이웃 수 """ def classify0(inX, dataSet, labels, k): dataSetSize = dataSet.shape[0] diffMat = tile(inX, (dataSetSize,1)) - dataSet sqDiffMat = diffMat**2 sqDistances = sqDiffMat.sum(axis=1) distances = sqDistances**0.5 sortedDistIndicies = distances.argsort() classCount={} for i in range(k): voteIlabel = labels[sortedDistIndicies[i]] classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1 sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True) return sortedClassCount[0][0]
예제: kNN을 이용하여 데이트 사이트의 만남 주선 개선하기
- 수집: 제공된 텍스트 파일
- 준비: 파이썬에서 텍스트 파일 구문 분석하기
- 분석: 데이터를 2D 플롯(plots)으로 만들기 위해 매스플롯라이브러리 사용하기
- 훈련: kNN 알고리즘에는 적용되지 않음
- 헬렌이 준 검사용 예제 ㄷ이터의 일부를 사용하기 위한 함수를 작성한다. 검사용 예제는 검사에 사용되지 않는 예제에 반해 분류가 되어 있고, 예측된 분류 항목이 실질적인 분류 항목과 일치하지 않으면 오류로 계산한다.
- 사용: 헬렌이 입력한 몇 가지 데이터를 토대로 누구를 좋아하게 될 것인지를 예측하는 데 사용할 수 있는 간단한 커맨드 라인 프로그램을 구축한다.
import matplotlib import matplotlib.pyplot as plt from numpy import array from numpy import * import operator //준비: 텍스트 파일의 데이터 구문 분석하기 def file2matrix(filename): //파일 읽어오기 fr = open(filename) //읽어온 파일의 줄 수가 얼마인지 센 후 저장 numberOfLines = len(fr.readlines()) //반환을 위한 NumPy 행렬 생성하기, numberOfLines*3 행렬을 0으로 채운 행렬 생성 returnMat = zeros((numberOfLines, 3)) classLabelVector=[] fr = open(filename) index = 0 //파일 내의 모든 줄을 반복 for line in fr.realines(): //strip을 이용하여 문자열 양 끝의 공백을 제거 line = line.strip() //'\t'으로 분할하여 리스트에 저장 listFromLine = line.split('\t') //처음 3개의 요소(feature)를 분할하여 위에서 생성한 행렬에 저장 // 연간 항공 마일리지 수, 비디오 게임으로 보내는 시간의 비율, 주당 아이스크림 소비량(리터) returnMat[index, :] = listFromLine[0:3] //리스트의 마지막 요소(feature)를 분할하여 classLabelVector에 저장 //1: 좋아하지 않았던 사람들, 2: 조금 좋아했던 사람들, 3: 많이 좋아했던 사람들 classLabelVector.append(listFromLine[-1]) index += 1 return returnMat, classLabelVector //분석: 매스플롯라이브러리로 scatter 플롯 생성하기 fig = plt.figure() ax = fig.add_subplot(111) ax.scatter(datingDataMat[:, 1]. datingDataMat[:, 2]) plt.show() ax.scatter(datingDataMat[:, 1], datingDataMat[:, 2], 15.0*array(datingLabels).astype(float), 15.0*array(datingLabels).astype(float)) //서로 다른 범위에 놓여있는 값을 다룰 경우에는 이들을 정규화하는 것이 일반적 //준비: 수치형 값 정규화하기 def autoNorm(dataSet): //dataSet의 최소값과 최대값을 구함 minVals = dataSet.min(0) maxVals = dataSet.max(0) //최대값 - 최소값으로 데이터의 범위를 구함 ranges = maxVals - minVals //dataSet의 크기만한 행렬을 만들어 초기화함 normDataSet = zeros(shape(dataSet)) m = dataSet.shape[0] //minVals를 m*1로 행렬화 한 후, dataSet 행렬에서 값을 뺌 //측정값-최소값 normDataSet = dataSet - tile(minVals, (m, 1)) //(측정값-최소값)/범위 normDataSet = normDataSet / tile(ranges, (m, 1)) return normDataSet, ranges, minVals def classify0(inX, dataSet, labels, k): dataSetSize = dataSet.shape[0] diffMat = tile(inX, (dataSetSize , 1)) - dataSet sqDiffMat = diffMat ** 2 sqDistances = sqDiffMat.sum(axis=1) distances = sqDistances**0.5 sortedDistIndicies = distances.argsort() classCount={} for i in range(k): voteIlabel = labels[sortedDistIndicies[i]] classCount[voteIlabel] = classCount.get(voteIlabel, 0) + 1 sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True) return sortedClassCount[0][0] //검사: 전체 프로그램으로 분류기 검사하기 def datingClassTest(): //현재 가지고 있는 데이터 중 10%로 분류기를 검사하여, 성능이 어느 정도인지 알아봄 hoRatio = 0.10 datingDataMat, datingLabels = file2matrix('datingTestSet2.txt') //데이터 정규화 normMat, ranges, minVals = autoNorm(datingDataMat) //정규화된 데이터의 전체 개수를 m에 저장 m = normMat.shape[0] //검사용 벡터의 개수를 계산 //현재 가진 데이터의 개수 * 0.1 numTestVecs = int(m*hoRatio) errorCount = 0.0 //검사용 벡터의 개수만큼 반복 for i in range(numTestVecs): //classify0(분류할 것, 분류된 데이터 행렬, 분류 항목, 뽑을 k) //normMat을 분류한다. normMat의 numTestVecs~m(끝)까지는 분류된 데이터 행렬, 분류 항목은 numTestVecs~m까지, k=3 classifierResult = classify0(normMat[i, :], normMat[numTestVecs:m, :], datingLabels[numTestVecs:m], 3) print("the classifier came back with: %d, the real answer is: %d" % (classifierResult, datingLabels[i])) //classifierResult이 datingLabels와 같지 않으면 errorCount++ if(classifierResult != datingLabels[i]): errorCount += 1.0 //에러개수/검사용벡터의개수 print("the total error rate is: %f" % (errorCount/float(numTestVecs))) //사용: 모두에게 유용한 시스템 만들기 def classifyPerson(): resultList = ['not at all', 'in small doses', 'in large doses'] percentTats = float(raw_input("percentage of time spent playing video games?")) ffMiles = float(raw_input("frequent flier miles earned per year?")) iceCream = float(raw_input("liters of ice cream consumed per year?")) //파일을 행렬화 datingDataMat, datingLabels = file2matrix('datomgTestSet2.txt') //데이터 정규화 normMat, ranges, minVals = autoNorm(datingDataMat) inArr = array([ffMiles, percentTats, iceCream]) //분류한 결과 = normMat(분류된 데이터)에서 (inArr-minVals)/ranges를 분류, datingLabels은 분류 항목, k=3 classifierResult = classify0((inArr - minVals)/ranges, normMat, datingLabels, 3) print("You will probably like this person: ", resultList[int(classifierResult) - 1])
댓글 없음:
댓글 쓰기